
UCR Researchers Unveil Revolutionary Method to Double Computer Operation Speed
Researchers from the University of California Riverside (UCR) brought to light a ground-breaking procedure at the 56th annual IEEE/ACM International Symposium on Microarchitecture. They demonstrated a policy where all computing components of a platform in fact simultaneously operate, achieving twice the operational speed and halving power consumption. The technology can be utilized across all processors and accelerators from smartphones to data center servers; it does require further development for improved efficiency though.
“You don’t need [for acceleration of calculations] to add new processors, because you already have them,” commented Hung-Wei Tseng, co-author of the study, and an adjunct professor at the UCR’s Electrical and Computer Engineering department. The strategy entails effective management of existing hardware rather than placing them in sequence.
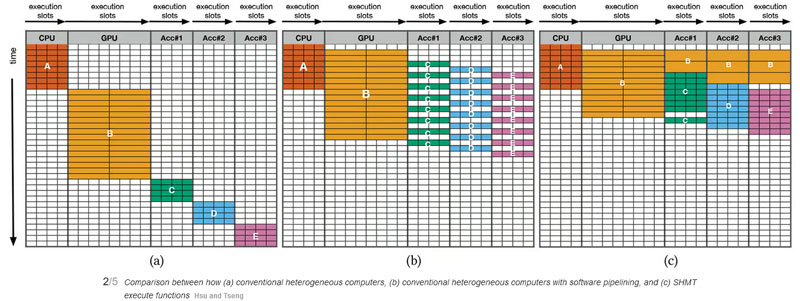
The team has created a platform that departs from traditional programming models, named Simultaneous and Heterogeneous Multithreading (SHMT). Instead of delivering data to a single computational component of the system in one time slot, the SHMT technology fosters parallel execution of code across all parts concurrently.

The SHMT incorporates a multithreading planning policy considering the quality-aware work-stealing (QAWS) parameter. The system requires fewer resources but helps maintain the quality and balance of workload. The execution system generates and partitions a set of virtual operations into one or more high-level operations. These are then used across multiple hardware resources simultaneously. Then, the SHMT execution system dispatches these high-level operations to task queues to run on the target equipment. As these tasks are not reliant on specific equipment, they can be re-directed to any component of the computing platform.
Utilizing a created testing platform, the researchers showcased new software libraries’ efficiency. The team created a novel device, a hybrid model akin to a smartphone, a miniature PC, or even a server. With the aid of the PCIe-based motherboard, they composed a ‘computer’ using a NVIDIA Nano Jetson module that amalgamates a quad-core ARM Cortex-A57 (CPU) along with 128 Maxwell architecture graphics cores (GPU). A Google Edge Accelerator (TPU) was connected to the board through an M.2 Key E slot.
The primary memory of the simulated system comprises 4GB LPDDR4 with a frequency of 1600MHz and speed of 25.6 Gbps where shared data are stored. The Edge TPU module further incorporates 8MB of memory, operating on Ubuntu Linux 18.04 as an Operating System.
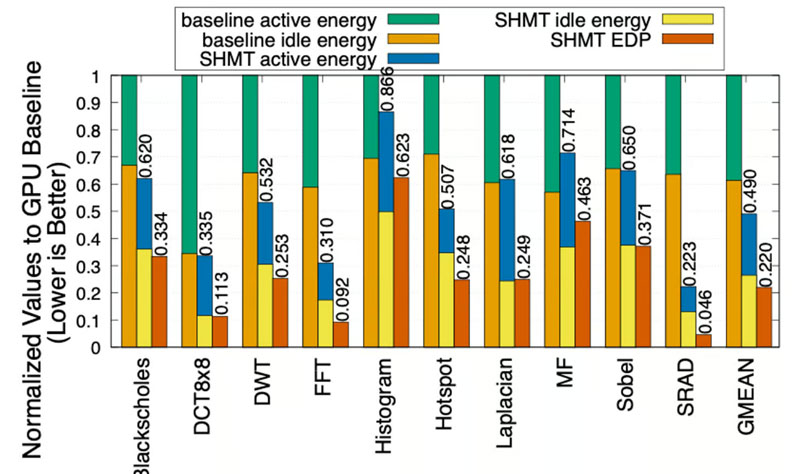
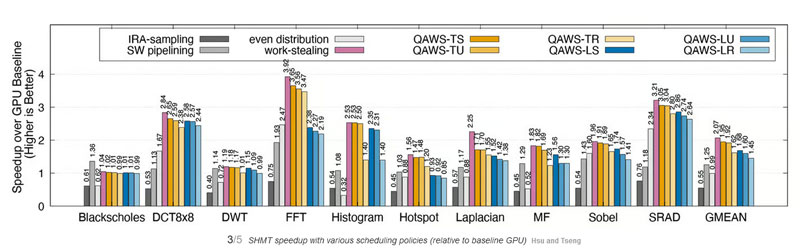
The findings specify that the SHMT package launched on the improvised heterogenous platform using standard applications for testing displays a 1.95-fold increase in computational speed. The technique reduces consumption by 51% compared to the conventional computational distribution method. If these tactics are scaled for use in data centers, the benefits would be massive whilst maintaining existing hardware. Although these proposed solutions are not ready for immediate implementation, they seem to offer promising prospects to interested entities.


